Bitstring Addresses and Routing
Addresses are useful for routing, because beyond specifying the destination of a message (or whatever else a network carries), they give information about where it should be sent next for it to end up there. In most real (computer) networks, addresses are controlled by a network authority. On the internet, ISPs allocate IP addresses to their customers, and those addresses are themselves allocated to the ISPs. Furthermore, IP addresses have digits which go from most-significant to least-significant, and the routing is easiest when nodes have only one upstream link, with which they share the most-significant address digits.
Because IP addresses are decided by authorities, the authorities can choose addresses which allow easy and efficient routing. The protocol also favours a particular topology. In a decentralised network, where nobody has the authority to say who can and can't use which address, or who can and can't be linked to who, we need another model.
Let's start with a toy example. (Be assured, dear reader, that the clumsy node positioning is the result of an algorithm, rather than a failure of judgement:)
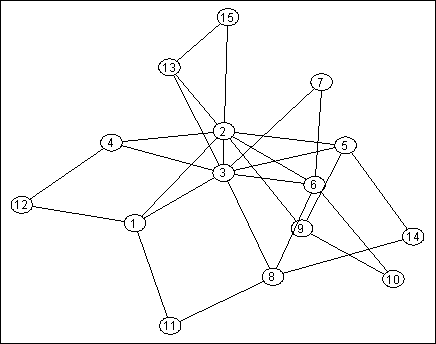
This network (let's call it $G$) has $15$ nodes, which is unrealistically small, but at least you can see all of it at once. If nobody gets to tell anyone else which address they should use, then each node must choose its own address.
What might the addresses look like? To accommodate an efficient routing algorithm, we need a way to work out who is near to a message's target address, so that we can route the message in the right direction. Mathematically, we can say the addresses are points in some metric space $H$ for which the metric $d_H$ correlates with the true network distance $d_G$. We're looking for an embedding $f : G \to H$ where each node $v \in G$ decides what $f(v)$ is, based on the information available to $v$.
We need to choose $H$ so that such an embedding is possible whatever $G$'s topology is. $H$ must have plenty of dimensions so that arbitrary networks can fit in it without being distorted too much, but should not be so big that addresses take too much information to specify. Since we're going to have to compute $d_H$ a lot, it would also be handy if $d_H$ were easy to compute. A natural choice is the Hamming cube, which for a given $n$ is the space of bitstrings $\mathbf{x} = (x_0, x_1, \ldots, x_{n-1})$ with $x_k \in \{0,1\}$, equipped with the Hamming distance $d_H(\mathbf{x},\mathbf{y})$ given by the number of indices $0 \le k < n$ for which $x_k \ne y_k$.
How should node $v$ choose a bitstring $f(v)$? We want $f(v)$ to be near to/far from $f(w)$ when $v$ is near to/far from $w$ respectively. Unfortunately, $v$ doesn't necessarily know what $d_G(v,w)$ is, or perhaps even that $w$ exists!
$v$ is at least aware of its own neighbours, and perhaps some other nodes whose true distance it has a rough idea about. Supposing $v$ is aware of other nodes $w_i$, $v$ can choose an address as follows: first, assign weights $\lambda_i \in \mathbb{R}$ to each $w_i$. Then for each $0 \le k < n$, compute the real number $$\tfrac{1}{2} + \sum \lambda_i \left(f(w_i)_k - \tfrac{1}{2}\right)$$ and update $f(v)_k$ to be whichever of $0$ or $1$ is nearer to it. This process can be iterated, beginning with random bitstrings.
(I am leaving a lot of details for another time. Well done for noticing.)
Of course I simulated it. Let's take a look at some of the results: the addresses are $n = 64$ bits long, but it is informative to see one bit at a time. Each image shows one address bit, red for $1$, blue for $0$.
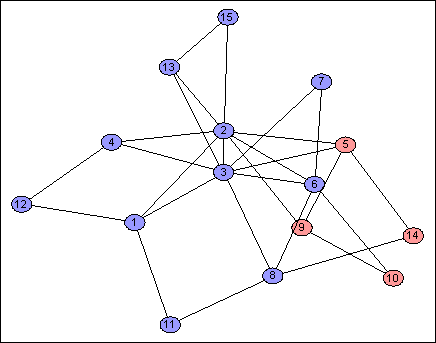
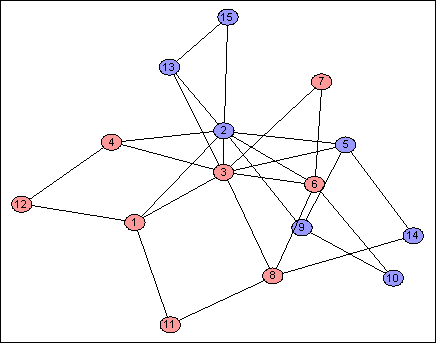
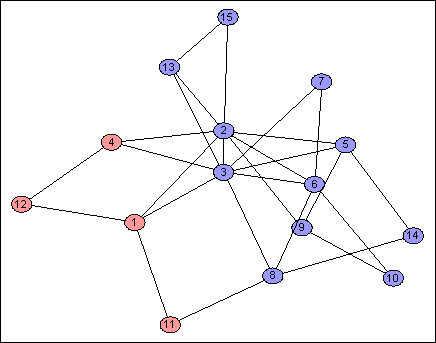
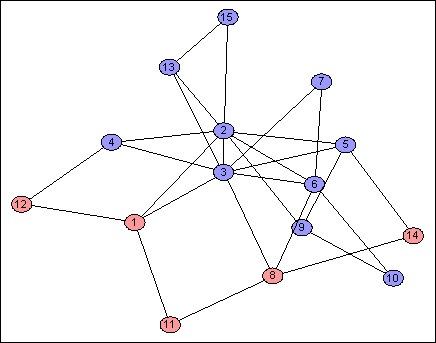
Each address bit partitions the network into two contiguous pieces, in a variety of different ways. This is useful because if $d_H(f(v),f(w))$ is small, then $v$ and $w$ must usually be partitioned together, so there aren't many "dividing lines" which separate them, so $d_G(v,w)$ is likely to be small, as required.
I'll be looking at the relationship between $d_G$ and $d_H$ in future posts, but here's some of the story:
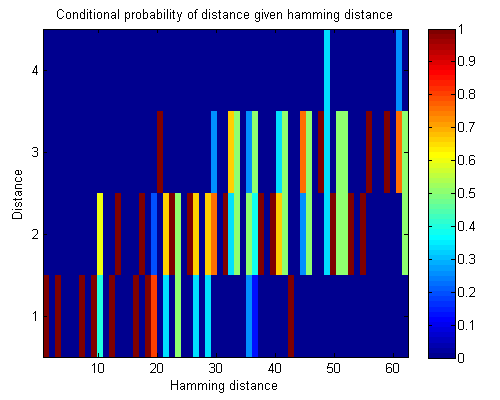
For each Hamming distance $d_H$, the graph shows the distribution of the true distance $d_G$. It's clear the two metrics are reasonably well correlated. The noise is actually not necessarily a big problem; it's possible that the embedding $f : G \to H$ stretches some parts of the network out more than others, so that for example a neighbouring link is worth $8$ bits in one place but $24$ elsewhere; so long as it's locally consistent enough, we should be fine. The real measure will be how efficient the message routing is; but that will have to wait.
A feature of this scheme is that each address bit is determined by the same process, for the whole network, independently of every other address bit. Given that we are doing the same thing $64$ times, it stands to reason that the outcomes will often be similar; there's nothing to stop two address bits from doing pretty much the same thing as each other. These two are identical except on four nodes:
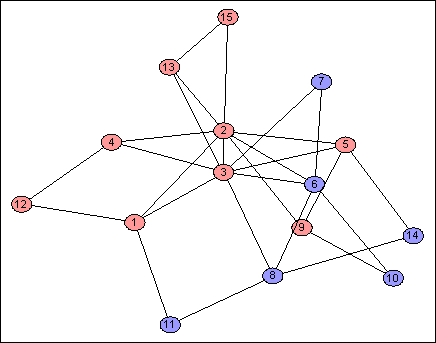
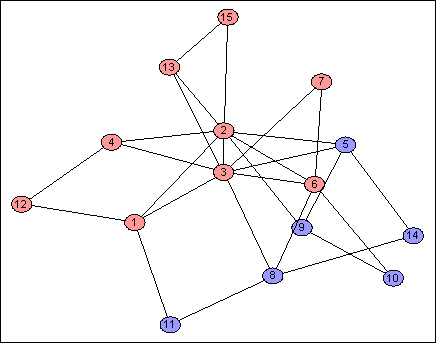
In fact, the vast majority of the bits are exactly identical (or are exact opposites) to other bits. We can measure the coefficient of determination $R^2$ between each pair of address bits, across all nodes: the dark red areas where $R^2 = 1$ indicate groups of bits which provide exactly the same information as each other. (The indices have been permuted to make these groups clear.)
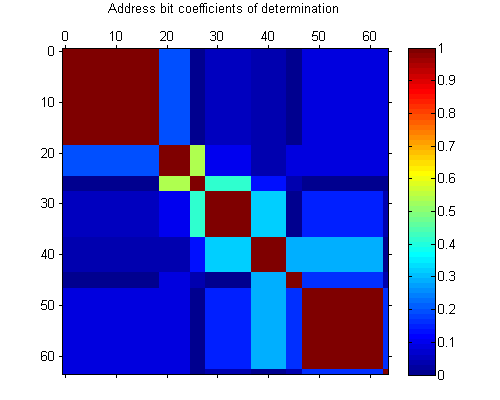
Strikingly, out of $64$ bits, only $8$ distinct partitions are produced. Fortunately, $8$ bits of information is plenty to distinguish between just $15$ nodes.
One last thing: the red and blue groups are not always contiguous:
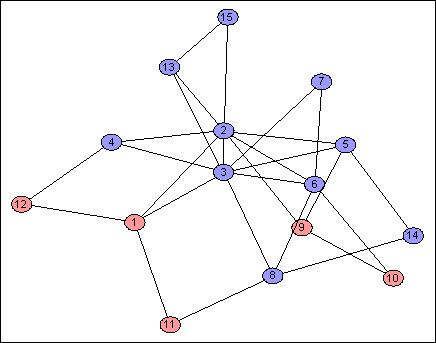
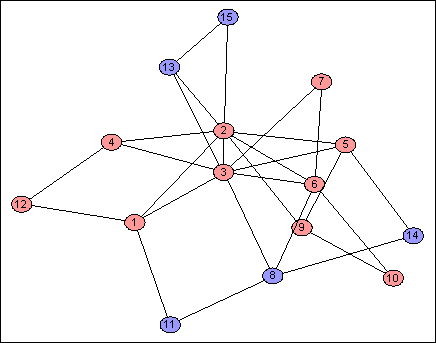
These comprise just $4$ of the address bits, including the only bit not in any group. The disconnected nodes do not mistakenly believe they are near to each other; rather, the weight of "distant" nodes between them has had the same effect on each of them.